Any machine learning model building task begins with a collection of data vectors wherein each vector consists of a fixed number of components. These components represent the measurements, known as attributes or features, deemed useful for the given machine learning task at hand. The number of components, i.e. the size of the vector, is termed as the dimensionality of the feature space. When the number of features is large, we are often interested in reducing their number to limit the number of training examples needed to strike a proper balance with the number of model parameters. One way to reduce the number of features is to look for a subset of original features via some suitable search technique. Another way to reduce the number of features or dimensionality is to map or transform the original features in to another feature space of smaller dimensionality. The Principal Component Analysis (PCA) is an example of this feature transformation approach where the new features are constructed by applying a linear transformation on the original set of features. The use of PCA does not require knowledge of the class labels associated with each data vector. Thus, PCA is characterized as a linear, unsupervised technique for dimensionality reduction.
Basic Idea Behind PCA
The basic idea behind PCA is to exploit the correlations between the original features. To understand this, lets look at the following two plots showing how a pair of variables vary together. In the left plot, there is no relationship in how X-Y values are varying; the values seem to be varying randomly. On the other hand, the variations in the right side plot exhibits a pattern; the Y values are moving up in a linear fashion. In terms of correlation, we say that the values in the left plot show no correlation while the values in the right plot show good correlation. It is not hard to notice that given a X-value from the right plot, we can reasonably guess the Y-value; however this cannot be done for X-values in the left graph. This means that we can represent the data in the right plot with a good approximation lying along a line, that is we can reduce the original two-dimensional data in one dimensions. Thus achieving dimensionality reduction. Of course, such a reduction is not possible for data in the left plot where there is no correlation in X-Y pairs of values.
PCA Steps
Now that we know the basic idea behind the PCA, let's look at the steps needed to perform PCA. These are:
We start with N d-dimensionaldata vectors, $\boldsymbol{x}_i, i= 1, \cdots,N$, and find the eigenvalues and eigenvectors of the sample covariance matrix of size d x d using the given data
We select the top k eigenvalues, k ≤ d, and use the corresponding eigenvectors to define the linear transformation matrix A of size k x d for transforming original features into the new space.
Obtain the transformed vectors, $\boldsymbol{y}_i, i= 1, \cdots,N$, using the following relationship. Note the transformation involves first shifting the origin of the original feature space using the mean of the input vectors as shown below, and then applying the transformation.
$\boldsymbol{y}_i = \bf{A}(\bf{x}_i - \bf{m}_x)$
The transformed vectors are the ones we then use for visualization and building our predictive model. We can also recover the original data vectors with certain error by using the following relationship
The mean square error (mse) between the original and reconstructed vectors is the sum of the eigenvalues whose corresponding eigenvectors are not used in the transformation matrix A.
Another way to look at how good the PCA is doing is by calculating the percentage variability, P, captured by the eigenvectors corresponding to top k eigenvalues. This is expressed by the following formula
$ P = \frac{\sum\limits_{j=1}^k \lambda_j}{\sum_{j=1}^d \lambda_j}$
A Simple PCA Example
Let's look at PCA computation in python using 10 vectors in three dimensions. The PCA calculations will be done following the steps given above. Lets first describe the input vectors, calculate the mean vector and the covariance matrix.
Next, we get the eigenvalues and eigenvectors. We are going to reduce the data to two dimensions. So we form the transformation matrix A using the eigenvectors of top two eigenvalues.
With the calculated A matrix, we transform the input vectors to obtain vectors in two dimensions to complete the PCA operation.
Looking at the calculated mean square error, we find that it is not equal to the smallest eigenvalue (0.74992815) as expected. So what is the catch here? It turns out that the formula used in calculating the covariance matrix assums the number of examples, N, to be large. In our case, the number of examples is rather small, only 10. Thus, if we multiply the mse value by N/(N-1), known as the small sample correction, we will get the result identical to the smallest eigenvalue. As N becomes large, the ratio N/(N-1) approaches unity and no such correction is required.
The above PCA computation was deliberately done through a series of steps. In practice, the PCA can be easily done using the scikit-learn implementation as shown below.
Before wrapping up, let me summarize a few takeaways about PCA.
You should not expect PCA to provide much reduction in dimensionality if the original features have little correlation with each other.
It is often a good practice to perform data normalization prior to applying PCA. The normalization converts each feature to have a zero mean and unit variance. Without normalization, the features showing large variance tend to dominate the result. Such large variances could also be caused by the scales used for measuring different features. This can be easily done by using sklearn.preprocessing.StandardScalar class.
Instead of performing PCA using the covariance matrix, we can also use the correlation matrix. The correlation matrix has a built-in normalization of features and thus the data normalization is not needed. Sometimes, the correlation matrix is referred to as the standardized covariance matrix.
Eigenvalues and eigenvectors are typically calculated by the singular value decomposion (SVD) method of matrix factorization. Thus, PCA and SVD are often viewed the same. But you should remember that the starting point for PCA is a collection of data vectors that are needed to compute sample covariance/correlation matrices to perform eigenvector decomposition which is often done by SVD.
A long while ago I had posted about how a "A Bunch of WeakClassifiers Working Together Can Outperform a Single Strong Classifier." Such a bunch of classifiers/regressors is called an ensemble. As mentioned in that post, bagging and boosting are two techniques that are used to create an ensemble of classifiers/regressors. In this post, I will explain how to build an ensemble of decision trees using gradient boosting. Before going into the details, however, let us first understand boosting, gradient boosting, and why the decision tree classifiers and regression trees are the most suitable candidates for creating an ensemble.
The individual units in an ensemble are known as weak learners. Such learners are brittle in nature, i.e. a small change in the training data can have a major impact on their performance. This brittle nature helps to ensure that the weak learners are not well-correlated with each other. The choice of the tree model for weak learners is popular because tree models exhibit decent brittleness and such models are easily trained without much computation effort.
Boosting is one technique to combine weak learners to obtain a single strong learner or model. Bagging is another such technique. In bagging, all weak learners learn in parallel and independent of other learners. Every learner in bagging looks at only a part of the training data or a subset of features or both. In boosting, the weak learners are build sequentially using the full training data and the results from the preceding weak learners. Thus, boosting builds an additivemodel and the output of the ensemble is taken as the weighted sum of the predictions of the weak learners.
In the original boosting algorithm AdaBoost, the successive weak learners try to improve the accuracy by giving more importance to those training examples that are misclassified by the prior weak learners. In gradient boosting, the results from the preceding weak learners are compared with the desired output to obtain a measure of the error which the next weak learner tries to minimize. Thus, the focus in gradient boost is on the residuals, i.e. the difference between the desired output and the actual output, rather than on those specific examples that were misclassified by the earlier learners. The term gradient is used because the error minimization is carried out by using the gradient of the error function. The sequence of successive trees are of identical depth from 1 (stump) to 4.
A Walk Through Example to Build a Gradient Boosted Regression Tree
Let us work through an example to clearly understand how gradient boosted trees are build. We will take a regression example because building a gradient boosted regression tree is easier to understand than a gradient boosted classification tree. The example consists of two predictors, fertilizer input (x0) and insecticide input (x1), and the output variable is the crop yield (y). The goal is to build a gradient boosted regression tree to predict the crop yield given the input numbers for x0 and x1.
We will build a tree that minimizes the squared error (mse) between the actual output and the predicted output. We begin by building a base learner that yields the same prediction irrespective of the values of the predictor variables. This base prediction, let us denote it as y_hat_0, equals average of the output variable y, y_bar. Next, we calculate the residuals, the difference between the actual output y and the predicted output to obtain the residuals as shown below.
The next step is to adjust the predictions by relating the residuals with x0 and x1. We do this by fitting a regression tree to the residuals. We will use a tree of depth 1. To build the tree, we find the feature and the cut-off or the threshold value that best partitions the training data to minimize the mean squared error (mse). For the root node, such a combination consists of predictor x1 and the cut-off value of 11.5. The resulting tree is shown below. This tree was build using the DecisionTreeRegressor of the Sklearn library. Let's look at the meanings of different entries shown in the tree diagram. The mse value of 181.889 in the internal node of the tree is nothing but the error value if the residuals_0 column is approximated by the column average which is being shown by "value = 0." The number of examples associated with a node in the tree is given by "samples."
The above tree shows residual approximation by -11.667 for those training examples whose x1 value is less than or equal to 11.5 and the approximation by 11.667 when x1 is greater than 11.5. Assuming a learning rate of 0.75, we combine the above tree with the base tree (stump) to obtain updated predictions and the next set of residuals as shown below. To understand how the updated predictions were calculated, consider the predictor variables x0=6 and x1=4. The above tree tells us that for x1=4, the residual should be approximated by -11.667. The previous prediction for this particular x0,x1 combination is 57.667. Thus, the new prediction in this case becomes 57.667+0.75*(-11.667) which equals 48.916.
With the new set of residuals, we again build a tree to relate x0, x1 with residuals_1. This tree is shown below.
We update the predictions. For the first training example, the updating leads to the prediction 48.916+0.75*(-2.717) which equals 46.879. These updated predictions, y_hat2, and the new residuals, residuals_2 are shown below.
The tree building process continues in this fashion to generate either the specified number of weak learners or to the acceptable level of error.
Now that we know how gradient boosted trees are created, let us finish the above example using the GradientBoostingRegressor from the Sklearn library as shown below. The number of learners has been specified as 10 and the depth is set to 1.
Let us convert the above regression example to a classification example by considering whether the crop yield was profitable or not based on fertilizer and insecticide costs. Thus, the output variable y now has two values, 0 (loss) and 1 (gain) as shown below.
Just like the procedure for building gradient boosted regression trees, we begin with a crude approximation for the output variable. The initial probability of class 1 over all the training examples, equal to 0.667, is taken as this approximation. The gradient boosted classifier is built using regression trees just like it is done while building gradient regression trees. The successive learners try to reduce the residuals, the difference between the y and the predicted probability.
Log Likelihood Loss Function and Log(odds)
The loss function minimized in the gradient boosted classification tree algorithm is the negative log likelihood. For a classification problem with two classes as we have, the negative log likelihood for the i-th training example is expressed by the following formula where p stands for the probability that the example is from class 1.
The loss is summed over all training examples to get the over all loss. The ratio p/(1-p) is called the odds or odds ratio, and often is expressed in terms of log(odds) by taking the natural log of the odds ratio. The probability p of an event and its log(odds) are related through the following equation:
Through some simple algebraic manipulation, we can also express the loss function as
Instead of calculating the gradient of the loss function with respect to p, it turns out that adjusting log(odds) offers a better way to minimize the loss function. Thus, taking the gradient of the loss function with respect to log(odd) results in the following expression:
The first term on the RHS of the equation is the negative of the desired output while the second term corresponds to the predicted probability (see the relationship between p and log(odds) above). The negative of the RHS in the above equation defines the residuals that we try to minimize by building successive trees via regression.
Back to Example
Coming back to our example, since the initial probability attached to every training example is 0.667 (ratio of class 1 labels and class 0 labels), the residuals are:
-0.667, 0.333, 0.333, 0.333, 0.333, -0.667
Let us try to fit a regression tree to the residuals at hand. Again, we will fit a tree of unit depth using the DecisionTreeRegressor from the Sklearn. The resulting tree shown below.
While in the case of the gradient regression trees, the "value" from the leaf nodes were directly used in the calculations of the updated residuals, we need to map "value" into log(odds) for calculating a new set of residuals in the present case. This mapping is done using the following relationship:
Let us try to understand the quantities in the RHS of the above expression. We will do so by referring to the right leaf node of the above tree. This leaf node has 5 samples that refer to the index "i" in the above expression. The item "value" in the leaf nodes is the residual for each example in the leaf node. There are five examples associated with the right leaf node; these are all but the first example of our data set. The previous probability is 0.667 for each of these examples. Thus, the mapped_log(odds) for these five examples are 5*0.133/(5*0.667*0.333), which equals 0.599. With 0.75 as the learning rate, the new log(odds) values for these five examples become 0.693(old log(odds)) + 0.75*(0.599) resulting in 1.142 for each of the five examples of the data set for which x0<9. Converting these log(odds) to probabilities, we see that 0.758 is the probability for the last five examples in the right leaf node to be from class 1. Carrying out similar calculations for the left leaf node, we end up with -1.559 as the updated log(odds) which translates to 0.174 as the probability that our first example in the data set is from class 1 or from the positive class.
Subtracting the updated probabilities from column y, we get a new set of residuals as shown below:
[-0.174, 0.242, 0.242, 0.242, 0.242, -0.758]
The regression tree built to fit these residuals is shown below.
We need to calculate the mapped_log(odds) again. The example associated with the right leaf in this case is the last example of the data set. The mapped log(odds) value for this example comes out as -4.132 following the formula for mapping shown above. The updated log(odds) value is then the 1.142(prior value) + 0.75* (-4.132). Converting the result into the probability, we get 0.123 as the probability that the last example in our data set comes from the positive class. Thus, it is classified as belonging to the negative (label 0) class. Let us now map the left leaf node value to log(odds) using the mapping formula.
This results in 0.906. Out of the five examples associated with the left leaf node, the four examples(all with y = 1) were together in the previous tree and had the updated log(odds) value 1.142 at that instance. The current log(odds) value for these four examples is then 1.142+0.75*0.906, equal to 1.821 which yields a probability value of 0.860. Thus, these four examples are correctly assigned the probability of 0.860 for the positive class. The remaining fifth example in the left node has a prior log(odds) value of -1.559. Thus, its updated log(odds) becomes -1.559+0.75*0.906, equal to -0.879. This gives 0.293 as the probability of this example from the positive class. Since the probability for the negative class is higher, this example is also correctly classified. At this stage, there is no need to add anymore learner because all examples have been correctly classified.
The above example was done to illustrate how the gradient boosted classifier builds its learners. Let us apply the GradientBoostingClassifier from the Sklearn library to check our step by step assembly of the learners explained above. We will print out the probability values to compare against our calculations.
from sklearn.ensemble import GradientBoostingClassifier
You can see that these probabilities are identical to those calculated earlier. Thus, you now know how to build a gradient boosted classifier.
Before You Leave
Let us summarize the post before you leave. Boosting relies on an ensemble of trees to perform regression and classification. The gradient boosted trees for regression and classification give excellent performance. Using the Sklearn library without paying much attention to the number of learners and tree depth can lead to over-fitting; so care must be taken. One disadvantage common to all ensemble methods is that the simplicity of understanding model that one gets using a single tree is lost. A speedier and more accurate and scalable version of gradient boosted trees is the extreme gradient boosted trees (XGBoost). The performance of XGBoost algorithm is at par with deep learning models and this model is very popular.
Often there is a confusion about data retrieval and information retrieval. This short post will attempt to clarify the difference between the two.
Information retrieval (IR) is a field of study dealing with the
representation, storage, organization of, and access to documents. The
documents may be books, reports, pictures, videos, web pages or
multimedia files. The whole point of an IR system is to provide a user
easy access to documents containing the desired information. One of the best
known example of an IR system is Google search engine. A data retrieval system is a database management system (DBMS).
The difference between an information retrieval system and a data retrieval system is that
– IR deals with unstructured/semi-structured data while a data
retrieval (a database management system or DBMS) deals with structured
data with well-defined semantics
– Querying a DBMS system produces exact/precise results or no results if no exact match is found
– Querying an IR system produces multiple results with ranking. Partial match is allowed.
Document Characterization
Three kinds of characteristics are associated with a document.
Metadata characterization
This kind of characterization refers to ownership, authorship and other
items of information about a document. The Library of Congress subject
coding is also an example of metadata. Another example of metadata is
the category headings at Internet search engine Yahoo. To standardize
category headings, many areas use specific ontologies, which are
hierarchical taxonomies of terms describing certain knowledge topics.
Presentation Characterization
This refers to attributes that control the formatting or presentation of a document.
Content Characterization
This refers to attributes that denote the semantic content of a document. Content characterization is of primary interest in IR. The common practice in IR is to represent a textual document by a set of keywords called index terms
or simply terms. An index term is a word or a phrase in a document
whose semantics give an indication of the document’s theme. The index
terms, in general, are mainly nouns because nouns have meaning by
themselves.
The same concept can be applied to images/multimedia documents to
characterize them in terms of words using the representation known aptly
as the Bag of Word (BoW) representation.
However, what are the words for images is a tricky question. One way
to define such words for images is through the use of vector
quantization which yields a set of code words (A code word is simply an
image patch of certain size) that can be used to assemble given images.
Once we are able to characterize images in terms of code words, various
attributes such as frequencies and joint frequencies of code words
occurrences can be computed to group images into meaningful groups. An
example of one such grouping is shown in the figure below where the
grouping of pictures is shown in the form of a graph.
While performing clustering, it is not uncommon to try a few different clustering methods. In such situations, we want to find out how similar are the results produced by different clustering methods. In some other situations, we may be interested in developing a new clustering algorithm or might be interested in evaluating a particular algorithm for our use. To do so, we make use of data sets with known ground truth so that we can compare the results against the ground truth. One way to evaluate the clustering results in all these situations is to make use of a numerical measure known as Rand index (RI). It is a measure of how similar two clustering results or groupings are.
Rand Index (RI)
RI works by looking at all possible unordered pairs of examples. If the number of examples or data vectors for clustering is n, then there are $\binom{n}{2}(=n(n-1)/2)$ pairs. For every example pair, there are three possibilities in terms of grouping. The first possibility is that the paired examples are always placed in the same group as a result of clustering. Lets count how often this happens over all pairs and represent that count by a. The second possibility is that the paired examples are never grouped together. Let's use b to represent the count of all pairs that are never grouped together. The third possibility is that the paired examples are sometimes grouped and sometimes not grouped together. The first two possibilities are treated as paired examples in agreement while the third possibility represents pairs in confusion. The RI of two groupings is then calculated by the following formula:
$\text{RI} = \frac{\text{Count of Pairs in Agreement}}{\text{Total Number of Pairs}} = \frac{(a+b)}{\binom{n}{2}}$
We can notice from the formula that RI can never exceed 1 and its possible lowest value is 0.
Let's take an example to illustrate RI calculation. Say we have five examples clustered into two clusters using two different clustering methods. The first method groups examples A, B, and C into one group and examples D and E into another group. The second clustering method groups A and B together and C, D, and E together. To compute RI for this example, lets first list all possible unordered pairs of five examples at hand. We have 10 (n*(n-1)/2) such pairs. These are: {A, B}, {A, C}, {A, D}, {A, E}, {B, C}, {B, D}, {B, E}, {C, D}, {C, E}, and {D, E}. Examining these pairs, we notice that the pair {A, B} and {D, E} are always grouped together by the both clustering methods. Thus, the value of a is two. We also notice that four pairs, {A, D}, {A, E}, {B, D}, and {B, E}, never occur together in any clustering result. Thus, the value of b is four. The Rand index (RI) is then 0.6.
Adjusted Rand Index (ARI)
RI suffers from one drawback; it yields a high value for pairs of random partitions of a given set of examples. To understand this drawback, think about randomly grouping a number of examples. When the number of partitions in each grouping, that is when the number of clusters, is increased, more and more example pairs are going to be in agreement because they are more likely to be not grouped together. This will result in a high RI value. Thus, RI is not able to take into consideration effects of random groupings. To counter this drawback, an adjustment is made to the calculations by taking into consideration grouping by chance. This is done by using a specialized distribution, the generalized hyper-geometric distribution, for modeling the randomness. The resulting measure is known as the adjusted Rand index (ARI).
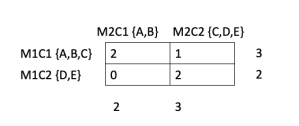
ARI is best understood using an example. So let's look at the example of two clustering results used earlier. Let's create a contingency table summarizing the results of two clustering methods. In this case, it is a 2x2 table wherein each cell of the table shows the number of times an example occurs in two clusters referenced by the corresponding row and column. M1C1 and M1C2 refer to two clusters formed by a hypothetical method-1. M2C1 and M2C2 similarly refer to two clusters formed by method-2. For clarity sake, I have included the examples forming the respective clusters next to M1C1, M1C2 etc. The top left cell has an entry of 2 because the clusters M1C1 and M2C1 share two examples, A and B. Entries in the other cells have similar meaning. The numbers to the right and below the contingency table show the sums along respective rows and columns.
To write the formula for ARI, lets generalize the entries of the contingency table using the following notation:
$n_{ij} = \text{Number of examples common to cluster i and cluster j}$
$a_i = \text{Sum of contingency cells in row i}$
$b_j = \text{Sum of contingency cells in column j}$
The ARI is then expressed as:
The first term in the numerator is known as index, and the second term as expected index. The first term in the denominator is called maximum index, and the second term of the denominator is same as the second term of the numerator. With these designations of the terms, the ARI is often expressed as
$\text{ARI} = \frac{\text{index - expected index}}{\text{maximum index - expected index}}$
Now lets go back to the contingency table for our example and calculate the different parts of the ARI formula first. We have:
Thus the index value for our example is 2; the expected index value is 1.6 (4*4/(5*4/2)). The maximum index value is 4. Therefore, the ARI for our example is (2 - 1.6)/(4 - 1.6), which equals 0.1666. We see that RI is much higher than ARI; this is typical of these indices. While RI always lies in 0-1; ARI can achieve a negative value also.
ARI is not the only measure to compare two sets of groupings. Mutual information based measure, adjusted mutual information (AMI), is also used for this purpose. May be in one of the future posts, I will describe this measure.
The ChatGPT is a large language model (LLM) from OpenAI that was
released a few months ago. Since then, it has created lots of excitement
in terms of a whole range of possible uses for it, lots and lots of
hype, and a lot of concern about harm that might result from its use.
Within five days after its release, the ChatGPT had over one million
users and that number has been growing since then. The hype arising from
ChatGPT is not surprising; the field of AI from its inception has been
hyped. One just need to be reminded of the Noble Prize winner Herbert
Simon’s statement “Machines will be capable, within twenty years, of
doing any work that a man can do” made in 1965. Several concerns about
the potential harm due to ChatGPT’s use have been expressed. It has been
found to generate inaccurate information as facts that is presented
very convincingly. Its capabilities are so good that Elon Musk recently
tweeted “ChatGPT is scary good. We are not far from dangerously strong
AI.”
Since ChatGPT’s release, many companies and researchers have been
playing with its capabilities and this has given rise to what is being
characterized as Generative AI. It has been used to write essays,
emails, and even scientific articles, prepare travel plans, solve math
problems, write code and create websites among many other usages. Many
companies have incorporated it into their Apps. And of course, Microsoft
has integrated it into its Bing search engine.
Given all the excitement about it, I decided to use it to build a linear
regression model. The result of my interaction with the ChatGPT are
presented below. The complete interaction was over in a minute or so;
primarily slowed by my one finger typing.
So, all it took to build the regression model was to feed the data and
let the ChatGPT know the predictor variables. Looks like a great tool.
But like any other tool, it needs to be used in a constructive manner. I
hope you like this simple demo of ChatGPT’s capabilities. I encourage
you to try on your own. OpenAI is free but you will need to register.
[This post was originally published on April 13, 2015.]
Vector space model is well known in information retrieval where each document is represented as a vector. The vector components represent weights or importance of each word in the document. The similarity between two documents is computed using the cosine similarity measure.
Although the idea of using vector representation for words also has been around for some time, the interest in word embedding, techniques that map words to vectors, has been soaring recently. One driver for this has been Tomáš Mikolov's Word2vec algorithm which uses a large amount of text to create high-dimensional (50 to 300 dimensional) representations of words capturing relationships between words unaided by external annotations. Such representation seems to capture many linguistic regularities. For example, it yields a vector approximating the representation for vec('Rome') as a result of the vector operation vec('Paris') - vec('France') + vec('Italy').
Word2vec uses a single hidden layer, fully connected neural network as shown below. The neurons in the hidden layer are all linear neurons. The input layer is set to have as many neurons as there are words in the vocabulary for training. The hidden layer size is set to the dimensionality of the resulting word vectors. The size of the output layer is same as the input layer. Thus, assuming that the vocabulary for learning word vectors consists of V words and N to be the dimension of word vectors, the input to hidden layer connections can be represented by matrix WI of size VxN with each row representing a vocabulary word. In same way, the connections from hidden layer to output layer can be described by matrix WO of size NxV. In this case, each column of WO matrix represents a word from the given vocabulary. The input to the network is encoded using "1-out of -V" representation meaning that only one input line is set to one and rest of the input lines are set to zero.
To get a better handle on how Word2vec works, consider the training corpus having the following sentences:
"the dog saw a cat", "the dog chased the cat", "the cat climbed a tree"
The corpus vocabulary has eight words. Once ordered alphabetically, each word can be referenced by its index. For this example, our neural network will have eight input neurons and eight output neurons. Let us assume that we decide to use three neurons in the hidden layer. This means that WI and WO will be 8x3 and 3x8 matrices, respectively. Before training begins, these matrices are initialized to small random values as is usual in neural network training. Just for the illustration sake, let us assume WI and WO to be initialized to the following values:
WI = W0 =
Suppose we want the network to learn relationship between the words "cat" and "climbed". That is, the network should show a high probability for "climbed" when "cat" is inputted to the network. In word embedding terminology, the word "cat" is referred as the context word and the word "climbed" is referred as the target word. In this case, the input vector X will be [0 1 0 0 0 0 0 0]t. Notice that only the second component of the vector is 1. This is because the input word is "cat" which is holding number two position in sorted list of corpus words. Given that the target word is "climbed", the target vector will look like [0 0 0 1 0 0 0 0 ]t.
With the input vector representing "cat", the output at the hidden layer neurons can be computed as
Ht = XtWI = [-0.490796 -0.229903 0.065460]
It should not surprise us that the vector H of hidden neuron outputs mimics the weights of the second row of WI matrix because of 1-out-of-V representation. So the function of the input to hidden layer connections is basically to copy the input word vector to hidden layer. Carrying out similar manipulations for hidden to output layer, the activation vector for output layer neurons can be written as
Since the goal is produce probabilities for words in the output layer, Pr(wordk|wordcontext) for k = 1, V, to reflect their next word relationship with the context word at input, we need the sum of neuron outputs in the output layer to add to one. Word2vec achieves this by converting activation values of output layer neurons to probabilities using the softmax function. Thus, the output of the k-th neuron is computed by the following expression where activation(n) represents the activation value of the n-th output layer neuron:
Thus, the probabilities for eight words in the corpus are:
The probability in bold is for the chosen target word "climbed". Given the target vector [0 0 0 1 0 0 0 0 ]t, the error vector for the output layer is easily computed by subtracting the probability vector from the target vector. Once the error is known, the weights in the matrices WO and WI
The probability in bold is for the chosen target word "climbed". Given the target vector [0 0 0 1 0 0 0 0 ]t, the error vector for the output layer is easily computed by subtracting the probability vector from the target vector. Once the error is known, the weights in the matrices WO and WI
can be updated using backpropagation. Thus, the training can proceed by presenting different context-target words pair from the corpus. In essence, this is how Word2vec learns relationships between words and in the process develops vector representations for words in the corpus.
Continuous Bag of Words (CBOW) Learning
The above description and architecture is meant for learning relationships between pair of words. In the continuous bag of words model, context is represented by multiple words for a given target words. For example, we could use "cat" and "tree" as context words for "climbed" as the target word. This calls for a modification to the neural network architecture. The modification, shown below, consists of replicating the input to hidden layer connections C times, the number of context words, and adding a divide by C operation in the hidden layer neurons. [An alert reader pointed that the figure below might lead some readers to think that CBOW learning uses several input matrices. It is not so. It is the same matrix, WI, that is receiving multiple input vectors representing different context words]
With the above configuration to specify C context words, each word being coded using 1-out-of-V representation means that the hidden layer output is the average of word vectors corresponding to context words at input. The output layer remains the same and the training is done in the manner discussed above.
Skip-Gram Model
Skip-gram model reverses the use of target and context words. In this case, the target word is fed at the input, the hidden layer remains the same, and the output layer of the neural network is replicated multiple times to accommodate the chosen number of context words. Taking the example of "cat" and "tree" as context words and "climbed" as the target word, the input vector in the skim-gram model would be [0 0 0 1 0 0 0 0 ]t, while the two output layers would have [0 1 0 0 0 0 0 0] t and [0 0 0 0 0 0 0 1 ]t as target vectors respectively. In place of producing one vector of probabilities, two such vectors would be produced for the current example. The error vector for each output layer is produced in the manner as discussed above. However, the error vectors from all output layers are summed up to adjust the weights via backpropagation. This ensures that weight matrix WO for each output layer remains identical all through training.
In above, I have tried to present a simplistic view of Word2vec. In practice, there are many other details that are important to achieve training in a reasonable amount of time. At this point, one may ask the following questions:
1. Are there other methods for generating vector representations of words? The answer is yes and I will be describing another method in my next post.
2. What are some of the uses/advantages of words as vectors. Again, I plan to answer it soon in my coming posts.