According to some estimates, the unstructured data accounts for about 90% of the data being generated everyday. A large part of unstructured data consists of text in the form of emails, news reports, social media postings, phone transcripts, product reviews etc. Analyzing such data for pattern discovery requires converting text to numeric representation in the form of a vector using words as features. Such a representation is known as vector space model in information retrieval; in machine learning it is known as bag-of-words (BoW) model.
In this post, I will describe different text vectorizers from sklearn library. I will do this using a small corpus of four documents, shown below.
corpus = ['The sky is blue and beautiful', 'The king is old and the queen is beautiful', 'Love this beautiful blue sky', 'The beautiful queen and the old king']
CountVectorizer
The CountVectorizer is the simplest way of converting text to vector. It tokenizes the documents to build a vocabulary of the words present in the corpus and counts how often each word from the vocabulary is present in each and every document in the corpus. Thus, every document is represented by a vector whose size equals the vocabulary size and entries in the vector for a particular document show the count for words in that document. When the document vectors are arranged as rows, the resulting matrix is called document-term matrix; it is a convenient way of representing a small corpus.
For our example corpus, the CountVectorizer produces the following representation.
from sklearn.feature_extraction.text import CountVectorizer import pandas as pd vectorizer = CountVectorizer() X = vectorizer.fit_transform(corpus) print(vectorizer.get_feature_names()) Doc_Term_Matrix = pd.DataFrame(X.toarray(),columns= vectorizer.get_feature_names()) Doc_Term_Matrix
['and', 'beautiful', 'blue', 'is', 'king', 'love', 'old', 'queen', 'sky', 'the', 'this']

The column headings are the word features arranged in alphabetical order and row indices refer to documents in the corpus. In the present example, the size of the resulting document-term matrix is 4×11, as there are 4 documents in the example corpus and there are 11 distinct words in the corpus. Since common words such as “is”, “the”, “this” etc do not provide any indication about the document content, we can safely remove such words by telling CountVectorizer to perform stop word filtering as shown below.
vectorizer = CountVectorizer(stop_words='english') X = vectorizer.fit_transform(corpus) print(vectorizer.get_feature_names()) Doc_Term_Matrix = pd.DataFrame(X.toarray(),columns= vectorizer.get_feature_names()) Doc_Term_Matrix
['beautiful', 'blue', 'king', 'love', 'old', 'queen', 'sky']

Although the document-term matrix for our small corpus example doesn’t have too many zeros, it is easy to conceive that for any large corpus the resulting matrix will be a sparse matrix. Thus, internally the sparse matrix representation is used to store document vectors.
N-gram Word Features
One issue with the bag of words representation is the loss of context. The BoW representation just focuses on words presence in isolation; it doesn’t use the neighboring words to build a more meaningful representation. The CountVectorizer provides a way to overcome this issue by allowing a vector representation using N-grams of words. In such a model, N successive words are used as features. Thus, in a bi-gram model, N = 2, two successive words will be used as features in the vector representations of documents. The result of such a vectorization for our small corpus example is shown below. Here the parameter ngram_range = (1,2) tells the vectorizer to use two successive words along with each single word as features for the resulting vector representation.
vectorizer = CountVectorizer(ngram_range = (1,2),stop_words='english') X = vectorizer.fit_transform(corpus) print(vectorizer.get_feature_names()) Doc_Term_Matrix = pd.DataFrame(X.toarray(),columns= vectorizer.get_feature_names()) Doc_Term_Matrix
['beautiful', 'beautiful blue', 'beautiful queen', 'blue', 'blue beautiful', 'blue sky', 'king', 'king old', 'love', 'love beautiful', 'old', 'old king', 'old queen', 'queen', 'queen beautiful', 'queen old', 'sky', 'sky blue']

It is obvious that while N-gram features provide context and consequently better results in pattern discovery, it comes at the cost of increased vector size.
TfidfVectorizer
Simply using the word count as a feature value of a word really doesn’t reflect the importance of that word in a document. For example, if a word is present frequently in all documents in a corpus, then its count value in different documents is not helpful in discriminating between different documents. On other hand, if a word is present only in a few of documents, then its count value in those documents can help discriminating them from the rest of the documents. Thus, the importance of a word, i.e. its feature value, for a document not only depends upon how often it is present in that document but also how is its overall presence in the corpus. This notion of importance of a word in a document is captured by a scheme, known as the term frequency-inverse document frequency (tf-idf ) weighting scheme.
The term frequency is a ratio of the count of a word’s
occurrence in a document and the number of words in the document. Thus,
it is a normalized measure that takes into consideration the document
length. Let us show the count of word i in document j by 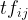
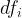
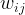

The sklearn library offers two ways to generate the tf-idf representations of documents. The TfidfTransformer transforms the count values produced by the CountVectorizer to tf-idf weights.
from sklearn.feature_extraction.text import TfidfTransformer
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
Doc_Term_Matrix = pd.DataFrame(tfidf.toarray(),columns= vectorizer.get_feature_names())
pd.set_option("display.precision", 2)
Doc_Term_Matrix

Another way is to use the TfidfVectorizer which combines both counting and term weighting in a single class as shown below.
from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer(ngram_range = (1,2),stop_words='english') tfidf = vectorizer.fit_transform(corpus) Doc_Term_Matrix = pd.DataFrame(tfidf.toarray(),columns= vectorizer.get_feature_names()) Doc_Term_Matrix
One thing to note is that the tf-idf weights are normalized so that the resulting document vector is of unit length. You can easily check this by squaring and adding the weight values along each row of the document-term matrix; the resulting sum should be one. This sum represents the squared length of the document vector.
HashingVectorizer
There are two main issues with the CountVectorizer and TdidfVectorizer. First, the vocabulary size can grow so much so as not to fit in the available memory for large corpus. In such a case, we need two passes over data. If we were to distribute the vectorization task to several computers, then we will need to synchronize vocabulary building across computing nodes. The other issue arises in the context of an online text classifier built using the count vectorizer, for example spam classifier which needs to decide whether an incoming email is spam or not. When such a classifier encounters words not in its vocabulary, it ignores them. A spammer can take advantage of this by deliberately misspelling words in its message which when ignored by the spam filter will cause the spam message appear normal. The HashingVectorizer overcomes these limitations.
The HashingVectorizer is based on feature hashing, also known as the hashing trick. Unlike the CountVectorizer where the index assigned to a word in the document vector is determined by the alphabetical order of the word in the vocabulary, the HashingVectorizer maintains no vocabulary and determines the index of a word in an array of fixed size via hashing. Since no vocabulary is maintained, the presence of new or misspelled words doesn’t create any problem. Also the hashing is done on the fly and memory need is diminshed.
You may recall that hashing is a way of converting a key into an address of a table, known as the hash table. As an example, consider the following hash function for a string s of length n:
$\text{hash(s)} = (s[0] + s[1] \cdot p +s[2]\cdot p^2 +\cdots + s[n-1] \cdot p^{n-1})\text{ mod }m$
The quantities p and m are chosen in practice to minimize collision and set the hash table size. Letting p = 31 and m = 1063, both prime numbers, the above hash function will map the word “blue” to location 493 in an array of size 1064 as per the calculations:
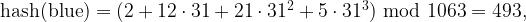
where letter b is replaced by 2, l by 12, and so on based on their positions in the alphabet sequence. Similarly, the word “king” will be hashed to location 114 although “king” comes later than “blue” in alphabetical order.
The HashingVectorizer implemented in sklearn uses the Murmur3
hashing function which returns both positive and negative values. The
sign of the hashed value is used as the sign of the value stored in the
document-term matrix. By default, the size of the hash table is set to 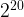
from sklearn.feature_extraction.text import HashingVectorizer vectorizer = HashingVectorizer(n_features=6,norm = None,stop_words='english') X = vectorizer.fit_transform(corpus) Doc_Term_Matrix = pd.DataFrame(X.toarray()) Doc_Term_Matrix

You will note that column headings are integer numbers referring to hash table locations. Also that hash table location indexed 5 shows the presence of collisions. There are three words that are being hashed to this location. These collisions disappear when the hash table size is set to 8 which is more than the vocabulary size of 7. In this case, we get the following document-term matrix.

The HashingVectorizer has a norm parameter that determines whether any normalization of the resulting vectors will be done or not. When norm is set to None as done in the above, the resulting vectors are not normalized and the vector entries, i.e. feature values, are all positive or negative integers. When norm parameter is set to l1, the feature values are normalized so as the sum of all feature values for any document sums to positive/negative 1. In the case of our example corpus, the result of using l1 norm will be as follows.

With norm set to l2, the HashingVectorizer normalizes each document vector to unit length. With this setting, we will get the following document-term matrix for our example corpus.

The HashingVectorizer is not without its drawbacks. First of all, you
cannot recover feature words from the hashed values and thus tf-idf
weighting cannot be applied. However, the inverse-document frequency
part of the tf-idf weighting can be still applied to the resulting
hashed vectors, if needed. The second issue is that of collision. To
avoid collisions, hash table size should be selected carefully. For very
large corpora, the hash table size of 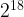
To summarize different vectorizers, the TfidfVectorizer appears a good choice and possibly the most popular choice for working with a static corpus or even with a slowing changing corpus provided periodic updating of the vocabulary and the classification model is not problematic. On the other hand, the HashingVectorizer is the best choice when working with a dynamic corpus or in an online setting.
