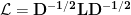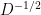- Classification model
- This implies whether you should be using a logistic classifier or a
multilayer neural network or a convolutional neural network or any other
suitable model
- Loss function
- A loss function provides a measure of how well the training is
proceeding and is needed to adjust the parameters of the classification
model being trained. The choice of a loss function depends upon whether
the model is being trained for a binary classification task or the
number of classes is many.
- Optimizer
- The training involves optimizing the chosen loss function by
repeatedly going over the training examples to adjust the model
parameters. Again, there are several optimizers available in all popular
machine learning and deep learning libraries to choose from.
In this blog post, I will focus on three commonly used loss functions
for classification to give you a better understanding of these loss
functions. These are:
- Cross Entropy Loss
- Binary Cross Entropy Loss
- Negative Log-likelihood Loss
What is Cross Entropy?
Let’s first understand entropy which measures uncertainty of an
event. We start by using C to represent a random event/variable which
takes on different possible class labels as values in a training set. We
use $p(c_i)$ to represent the probability that the class label of a training example is $c_i$, i.e. C equals $c_i$ with probability p. The entropy of the training set labels can be then expressed as below where the summation is carried over all possible labels:
$E(C) = -\sum_i p(c_i)$
It is easy to see that if all training examples are from the same
class, then the entropy is zero, and there is no uncertainty about the
class label of any training example picked at random. On the other hand,
if the training set contains more than one class label, then we have
some uncertainty about the class label of a randomly picked training
example. As an example, suppose our training data has four labels: cat,
dog, horse, and sheep. Let the mix of labels in our training data be cat
40%, dog 10%, horse 25%, and sheep 25%. Then the entropy of the
training set using the natural log is given by
Entropy of our Training Set = -(0.4 log0.4 + 0.1log0.1 + 0.25log0.25 + 0.25log0.25 = 1.29
The entropy of a training set will achieve its maximum value when
there are equal number of training examples from each category.
Let’s consider another random variable $\hat C$ which denotes the labels predicted by the model for a training example.
Now, we have two sets of label distributions, one of true (target)
labels in the training set and another of predicted labels. One way to
compare these two label distributions is to extend the idea of entropy
to cross entropy. It is defined as
$H(C,\hat{C}) = -\sum_i p(c_i)\log p(\hat{c}_i)$
Note that the cross entropy is not a symmetric function. Suppose the
classifier that you have trained produces the following distribution of
predicted labels: cat 30%, dog 15%, horse 25%, and sheep 30%. The cross
entropy of the target and the predicted labels distribution is then
given by
Cross Entropy(target labels, predicted labels) = -(0.4log0.3+ 0.1log0.15 + 0.25log0.25 + 0.25log0.3 = 1.32
The difference between the cross entropy value of 1.32 and the
entropy of target labels of 1.29 is a measure of how close the predicted
label distribution is to the target distribution.
While you are looking at your classifier, your friend pops in to tell
you how well his classifier is doing. His classifier is producing the
following distribution of predicted labels: cat 30%, dog 20%, horse 20%,
and sheep 30%. You look at his numbers and tell him that your
classifier is better that his because the cross entropy measure of your
classifier, 1.32, is closer to the target entropy of 1.29 than the cross
entropy measure of 1.35 of his classifier.
Cross Entropy Loss
The above definition of cross entropy is good for comparing two
distributions or classifiers at a global level. However, we are
interested in having a measure at the training examples level so that it
can be used to adjust the parameters of the classifier being trained.
To see how the above concept of cross entropy can be applied to each and
every training example, let’s consider a training example inputted to a
3-class classifier to classify images of cats, dogs, and horses. The
training example is of a horse. Using one-hot encoding for class labels,
the target vector for the input image of the horse will be [0, 0, 1].
Since it is a 3-class problem, the classifier has three outputs as depicted below. where the output of the softmax stage is a vector of probabilities. Note that the classifier output is a vector of numbers, called logits. These are converted to a vector of probabilities by the softmax function as shown.
 |
|

Thus, we have two sets of probabilities: one given by the target
vector t and the second given by the output vector o. We can thus use the cross entropy measure defined earlier to express the cross entropy loss. Plugging in the numbers, the cross entropy loss value is calculated as
-(0*log(0.275) + 0*log(0.300) + 1*log(0.425)) -> 0.856
You can note that this loss would tend towards zero if the output
probability for the class label horse goes up. This means that if our
classifier is making correct predictions with increasing probabilities,
the cross entropy loss will be small.
Since batches of training vectors are inputted at any training
instance, the cross entropy loss for the batch is found by summing the
loss over all examples.
While using the cross entropy loss in PyTorch, you do not need to
worry about the softmax calculations. The cross entropy loss function in
PyTorch takes logits as input and thus has a built-in softmax function.
You can use the loss function for a single example or for a batch. The
following example illustrates the use of cross entropy loss function for
a single example.
import torch
import torch.nn.functional as F
out = torch.tensor([3.05, 3.13, 3.48])
target = torch.tensor([0.0, 0.0, 1.0])
loss =F.cross_entropy(out,target)
print(loss)
tensor(0.8566)
Binary Cross Entropy (BCE) Loss
Let’s consider a training model for a two-class problem. Let’s input
an example from class 1 to the model, i.e the correct label is y = 1. The model predicts with probability p the input class label to be 1. The probability for the input class label not being 1 is then 1-p. The following formula captures the binary cross entropy loss for this situation:
$BCELoss = -(y*log(p) + (1-y)*log(1-p))$
Assuming p equal to 0.75, the BCELoss is 0.287. It is easy to see that when the predicted probability p approaches 1, the loss approaches 0.
loss = nn.BCELoss()
out= loss(torch.tensor([0.75]),torch.tensor([1.0]))
print(out)
tensor(0.2877)
The BCELoss function is generally used for binary classification
problems. However, it can be used for multi-class problems as well. The
BCELoss formula for C classes is then expressed as shown below where $y_k$ is the target vector component and $p_k$ is the predicted probability for class k.
$BCELoss = -\frac{1}{C}\sum_k (y_k * log(p_k) + (1-y_k)*log(1-p_k))$
Let’s use the above formula with a three-class problem where the
predicted probabilities for an input for three classes are [0.277,
0.299, 0.424]. The training example is from class 3. The target tensor
in this case is then [0.0,0.0,1.0]. The BCELoss value for this situation
will be then
-(log(1-0.277) + log(1-0.299) + log(0.424))/3 –> 0.5125
We will now use the BCELoss function to validate our calculation.
out = loss(torch.tensor([0.277, 0.299, 0.424]), torch.tensor([0.0,0.0,1.0]))
print(out)
tensor(0.5125)
Note that the first argument in BCELoss() is a tensor of
probabilities and the second argument is the target tensor. This means
that the model should output probabilities. Often the output layer has
the Relu function as the activation function. In such cases, Binary cross entropy with logits loss function
should be used which converts the Relu output to probabilities before
calculating the loss. This is shown below in the example where the first
argument is a tensor of Relu output values. The calulations of the
probabilities is also shown using the sigmoid function. You can use
these probabilities in the BCELoss function to check whether you get the
same loss value or not via these two different calculations.
loss = nn.BCEWithLogitsLoss()
out = loss(torch.tensor([1.8, 0.75]),torch.tensor([1.0,0.0]))
print (out)
print(torch.sigmoid(torch.tensor([1.8,0.75])))# Will output class probabilities
tensor(0.6449)
tensor([0.8581, 0.6792])
If we input the probabilities calculated above using the sigmoid
function in the BCELoss function, we should get the same loss value.
loss = nn.BCELoss()
out= loss(torch.tensor([0.858,0.679]),torch.tensor([1.0, 0.0]))
print(out)
tensor(0.6447)
Negative Log Likelihood Loss
The negative log-likelihood loss (NLLLoss in PyTorch) is used for
training classification models with C classes. The likelihood means what
are the chances that a given set of training examples, $X_1,X_2,⋯,X_n$ was generated by a model that is characterized by a set of parameters represented by 𝜽. The likelihood 𝐿 thus can be expressed as
$𝐿(X_1,X_2,⋯,X_n|\theta)=𝑃(X_1,X_2,⋯,X_n|\theta)$.
Assuming that all training examples are independent of each other, the
right hand side of the likelihood 𝐿 expression can be written as
$𝐿(X_1,X_2,⋯,X_n|\theta)= \prod(𝑃(X_1|\theta)𝑃(X_2|\theta)...𝑃(X_n|\theta)$.
Taking the log of the likelihood converts the right hand side
multiplications to a summation. Since we are interested in minimizing
the loss, the negative of the log likelihood is taken as the loss
measure. Thus
$-log𝐿(X_1,X_2,⋯,X_n|\theta) = -\sum_{i=1}^{n}log(𝑃(X_i|\theta)$
The input to the NLLLoss function is log probabilities of each class
as a tensor. The size of the input tensor is (minibatch size, C). The
target specified in the loss is a class index in the range [0,C−1] where
C = number of classes. Let’s take a look at an example of using NLLLoss
function.
loss = nn.NLLLoss()
input = torch.tensor([[-0.6, -0.50, -0.30]])# minibatch size is 1 in this example. The log probabilities are all negative as expected.
target = torch.tensor([1])
output = loss(input,target)
print(output)
tensor(0.5000)
It can be noted that the NLLLoss value in this case is nothing but
the negative of the log probability of the target class. When the class
probabilities are not directly available as usually is the case, the
model output needs to go through the LogSoftmax function to get log
probabilities.
m = nn.LogSoftmax(dim=1)
loss = nn.NLLLoss()
# input is of size N x C. N=1, C=3 in the example
input = torch.tensor([[-0.8956, 1.1171, 1.3302]])
# each element in target has to have 0 <= value < C
target = torch.tensor([1])
output = loss(m(input), target)
print(output)
tensor(0.8634)
The cross entropy loss and the NLLLoss are mathematically equivalent.
The difference between the two arises in how these two loss functions
are implemented. As I mentioned earlier the cross entropy loss function
in Pytorch expects logits as input, and it includes a softmax function
while calculating the cross entropy loss. In the case of NLLLoss, the
function expects log probabilities as input. Lacking them, we need to
use LogSoftmax function to get the log probabilities as shown above.
There are a few other loss functions available in PyTorch and you can check them at the PyTorch documentation site. I hope you enjoyed reading my explanation of different loss functions. Contact me if you have any question.