Neuro-symbolic AI, also known as symbolic neural integration or hybrid AI, has been in news lately. It is an approach that combines symbolic reasoning and neural networks to create more robust and flexible artificial intelligence systems. This integration aims to leverage the strengths of both symbolic and neural approaches, addressing some of the limitations each paradigm faces independently.
Let's look at the following image to understand the need for the neuro-symbolic approach. The deep learning model looking at the input image comes to a conclusion that the image depicts a cow that is 5.2 meter long. Obviously, the system has been trained to recognize cows and other objects but is unable to reason that cows are not that long. This is not surprising as deep learning models are excellent at recognizing features but have no capability to understand or draw conclusions based on the spatial relationships between the detected features. One way to provide such capabilities is to integrate symbolic reasoning along with the feature detection and pattern recognition capabilities of deep neural networks, and thus the interest in the neuro-symbolic approach.

The ways Neuro-Symbolic AI can help
- Improved Reasoning: Integrating symbolic reasoning with neural networks can enhance AI's ability to understand and apply common sense knowledge, making it more adept in real-world scenarios.
- Medical Diagnosis: Neuro-symbolic approaches can be applied to medical diagnosis, where symbolic rules can be used to represent expert knowledge, and neural networks can learn from diverse patient data to improve diagnostic accuracy.
- Robotics and Autonomous Systems: Combining symbolic reasoning with neural networks can enhance the decision-making capabilities of robots, allowing them to navigate complex environments and handle uncertainty.
- Natural Language Understanding: Neuro-symbolic AI can be used to improve natural language understanding systems by combining semantic representation with the ability to learn from diverse textual data.
- Financial Fraud Detection: Integrating symbolic rules for detecting fraud patterns with neural networks that can adapt to new, emerging fraud trends can enhance the accuracy and robustness of fraud detection systems
Challenges and Approaches
- Neural Networks with Symbolic Inductive Biases: This approach aims to build neural architectures with inductive biases derived from symbolic AI, such as logical operations, algebraic reasoning, or compositional structure. For example, graph neural networks can inject relational inductive biases, while neural programmer-interpreters combine neural modules with program-like operations.
- Augmenting Neural Models with External Memory/Reasoning: Rather than directly encoding symbolic knowledge in the neural architecture, another approach uses external memory or reasoning components that interact with a neural network. Examples include memory augmented neural networks, neural semantic encoders, and neural-symbolic concept learners.
- Differentiable Inductive Logic Programming: Inspired by inductive logic programming (ILP) in symbolic AI, this approach uses neural networks to learn first-order logic rules or program-like primitives in a differentiable way that integrates symbolic reasoning into end-to-end training.
- Learning Symbolic Representations from Data: Techniques in this area aim to have neural networks automatically learn disentangled, symbolic-like representations from raw data in an unsupervised or self-supervised manner. Examples include sparse factor graphs, conceptor-based models, and neuro-symbolic concept invention.
 between node I and node j is measured by looking at all possible paths between the two nodes. The
between node I and node j is measured by looking at all possible paths between the two nodes. The  of a graph
of a graph  measuring the similarity between different node pairs can be obtained by the following expression:
measuring the similarity between different node pairs can be obtained by the following expression:![S = [s_{ij}] = [I + \epsilon^2 D - \epsilon A]^{-1}](https://s0.wp.com/latex.php?latex=S+%3D+%5Bs_%7Bij%7D%5D+%3D+%5BI+%2B+%5Cepsilon%5E2+D+-+%5Cepsilon+A%5D%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002) ,
, is an identity matrix,
is an identity matrix,  is the degree matrix, and
is the degree matrix, and  is the adjacent matrix of the graph
is the adjacent matrix of the graph  is a small positive constant.Given two graphs
is a small positive constant.Given two graphs  and
and 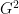 , the DeltaCon distance measure is computed using the following relationship:
, the DeltaCon distance measure is computed using the following relationship: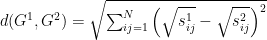






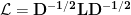 ,
,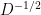 are given as
are given as 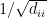 and non-diagonal components being zero. The following is the normalized Laplacian of the matrix L shown earlier.
and non-diagonal components being zero. The following is the normalized Laplacian of the matrix L shown earlier.
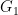 and
and  , the spectral graph distance will be computed as
, the spectral graph distance will be computed as

